使用索引
What Are Indexes & Why Do We Use Them?
索引可提升資料庫的查詢、更新、刪除速度。
通常資料庫的資料在建立時除了 ID 都沒有順序。建立索引(有序串列)就是針對特定 Field 加以排序。
排序後的 Field 就好比指標,會指向資料所在位置,因此可加快讀取速度。
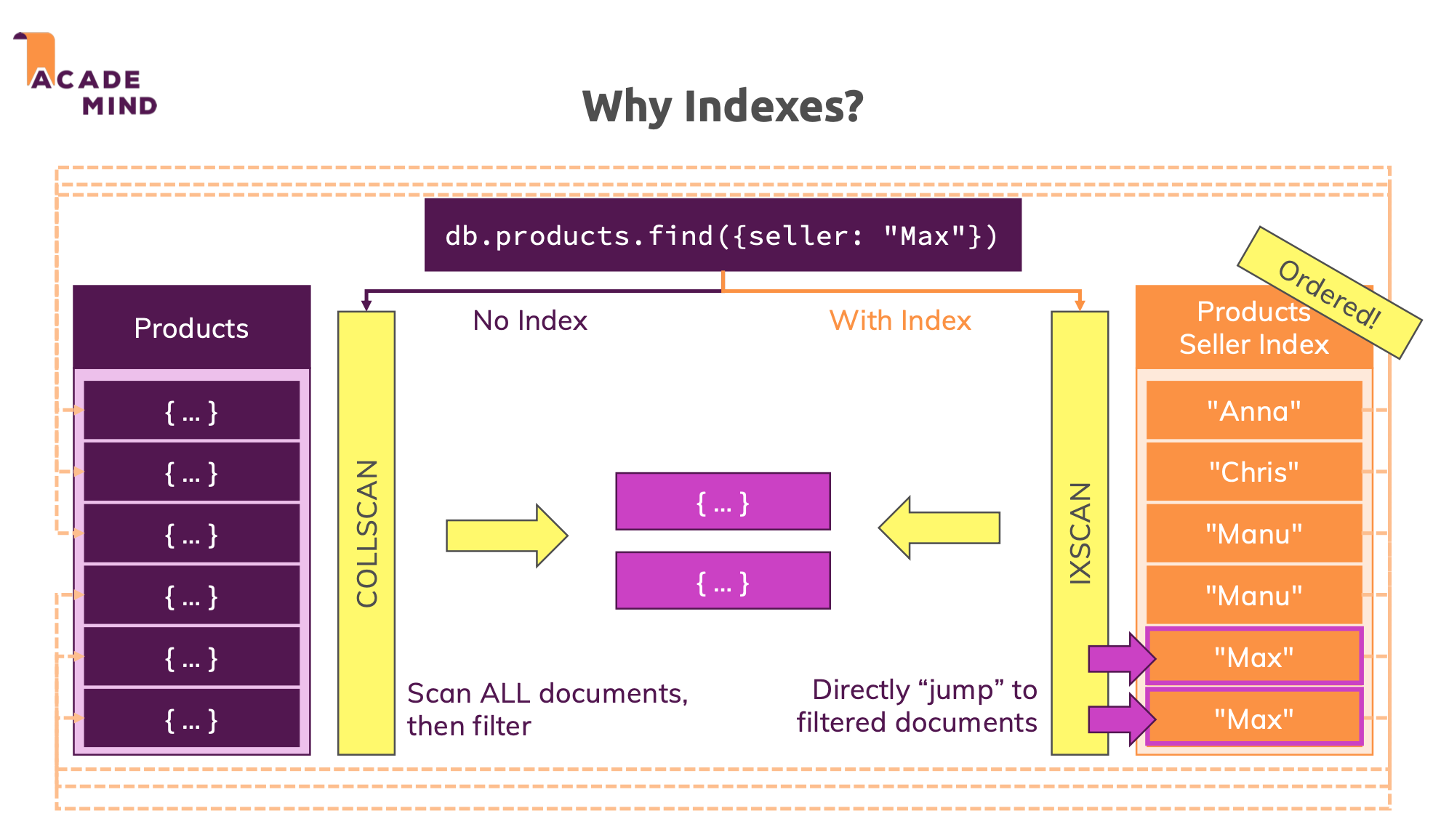
如下圖,左側是 Products 集合的所有 Document。
在尚未建立索引時,要取回資料必須掃描所有的 Document 再篩選資料(COLLSCAN)。
但若針對 Collection 內特定的 Field 建立索引,
則查找該 Field 資料時可從已排序的資料快速取得其所屬 Document(IXSCAN)。
Don't Use Too Many Indexes!
建立 Index 雖可提升讀取效能,但在寫入資料時反而會降低效能。
因此必須有計畫的建立索引,而非有多少 Field 就建立多少索引。
Adding a Single Field Index
建立索引前,可使用 explain() 觀察讀取資料所需時間。指令如下:
db.collection_name.explain("executionStats").find({field: value})
上述指令回傳的資料中,executionStats.executionTimeMillis 即是讀取資料所需的毫秒數。
createIndex()
使用 createIndex() 可建立索引,範例如下:
# 建立排序規則為 ASC 的索引
db.collection_name.createIndex({field: 1})
# 建立排序規則為 DESC 的索引
db.collection_name.createIndex({field: -1})
Understanding Index Restrictions
使用 dropIndex() 可移除索引,範例如下:
db.collection_name.dropIndex({field: 1})
db.collection_name.dropIndex({field: -1})
回傳資料占比影響索引的必要性
讀取索引化的資料時,回傳資料的數量愈接近 Document 總量,效能愈差。
因為此時不僅要從索引當中找出資料的指標,更要對集合中大多數資料執行 COLLSCAN。
反觀未建立索引時,同樣會對集合中大多數資料執行 COLLSCAN,卻不需從索引當中找出資料的指標。
換言之,當讀取資料時僅取回少量資料(盡量不高於 Document 總量的兩成)時,索引對效能的提升最有幫助。
Creating Compound Indexes
讀取資料時,若 Filter 篩選條件不只一個,可視情況建立複合索引。
資料變化太少的 Field 不適合建立索引
如果某個 Field 僅儲存布林值,則可能的值不外乎 true or false,此時建立索引的意義不大。
即使儲存值為字串型別,若儲存的內容僅限於「男、女、其他」三種,建立索引的意義同樣不大。
複合索引只能由左至右參考
db.collection_name.createIndex({field1: 1, field2: 1, field3: 1,...})
如上範例所示,建立複合索引非常簡單。
值得注意的是,按上述範例的邏輯而言,在讀取資料時若僅以 field2 或 field3 為篩選條件,
MongoDB 並不會參考索引。只有在以 field1 或 field1 + field2 或 field1 + field2 + field3
為篩選條件時,才會參考索引。
Using Indexes for Sorting
讀取已建立索引的資料時,可利用索引提升排序效能。
尤其是在資料數量龐大時,未經索引而排序資料可能超過 MongoDB 排序用記憶體的上限(32 MB),
此時就可善用索引迴避記憶體上限的問題。
# 先建立索引
db.collection_name.createIndex({field1: 1, field2: 1, field3: 1,...})
# 讀取資料時利用索引排序
db.collection_name.find({field1: value1}).sort({field2: value2})
Understanding the Default Index
getIndexes() 可檢視 Collection 中有哪些索引
db.collection_name.getIndexes()
Configuring Indexes
使用 createIndex 建立索引時可輸入選項,例如建立 unique index。
db.collection_name.createIndex({fieldName: 1}, {unique: true})
Understanding Partial Filters
預期頻繁使用特定篩選條件讀取資料時,與其對所有資料新增索引,不如只對符合特定條件的資料新增索引。
利用 partialFilterExpression 可針對 Field 當中符合特定條件的值設定索引,不符合條件的值則不會新增索引。
# Partial Filters 也可用於複合索引
db.collection_name.createIndex(
{field1: 1},
{partialFilterExpression: {field2: value}}
)
Applying the Partial Index
假設集合 collection1 的 field1 是 unique index。 在預設情況下,若有任兩筆 Documewnt 不存在 field1,就是違反唯一索引的限制。 若要對 field1 設定唯一索引,又想保留 field1 可有可無的彈性, 則需在建立索引時設定 partialFilterExpression。
db.collection_name.createIndex(
{field: 1},
{unique: true,
partialFilterExpression: {field1: {$exists: true}}})
Understanding the Time-To-Live (TTL) Index
建立索引時,可使用選項 expireAfterSeconds,如此可使資料在一定秒數後自動刪除。
值得注意的是,這個機制是每隔六十秒檢查一次,因此資料實際存在的時間通常會大於設定的秒數。
註:TTL 適合用於 Session 等應用情境。
db.sessions.createIndex({createdAt: 1}, {expireAfterSeconds: 6000})
Understanding Covered Queries
如果索引當中含有讀取資料庫時預期取得的所有資料,就算是符合 Covered Queries(覆蓋查詢)的定義。 操作 MongoDB 時,善用 Projection 實現覆蓋查詢可提升讀取效能。
# 假設集合中所有文件都是相同結構:{name: "nameInt"}
db.collection_name.insertMany([{name: "name1"}, {name: "name2"},...])
# 建立索引
db.collection_name.icreateIndex({name: 1})
# 如果讀取資料時不需取得 _id,透過 explain("executionStats") 的回傳結果可知,
# line 10 的效能優於 line 9。因為 _id 並未建立索引,導致 line 9 除了要檢查 Keys,
# 也要檢查 Docs。反觀 line 10 只要檢查 Keys 即可,因此效能較佳。
db.collection_name.explain("executionStats").find({name: "name1"})
db.collection_name.explain("executionStats").find({name: "name1"}, {_id: 0, name: 1})
How MongoDB Rejects a Plan
資料庫讀取資料時,根據資料表或索引的設計、查詢條件的組合,
同樣的讀取結果可能有多種讀取資料的方法(Plan)。
MongoDB 會比較各種 Plan,找出效能最好的 Plan(Winning Plan)。
Winning Plan 示意圖
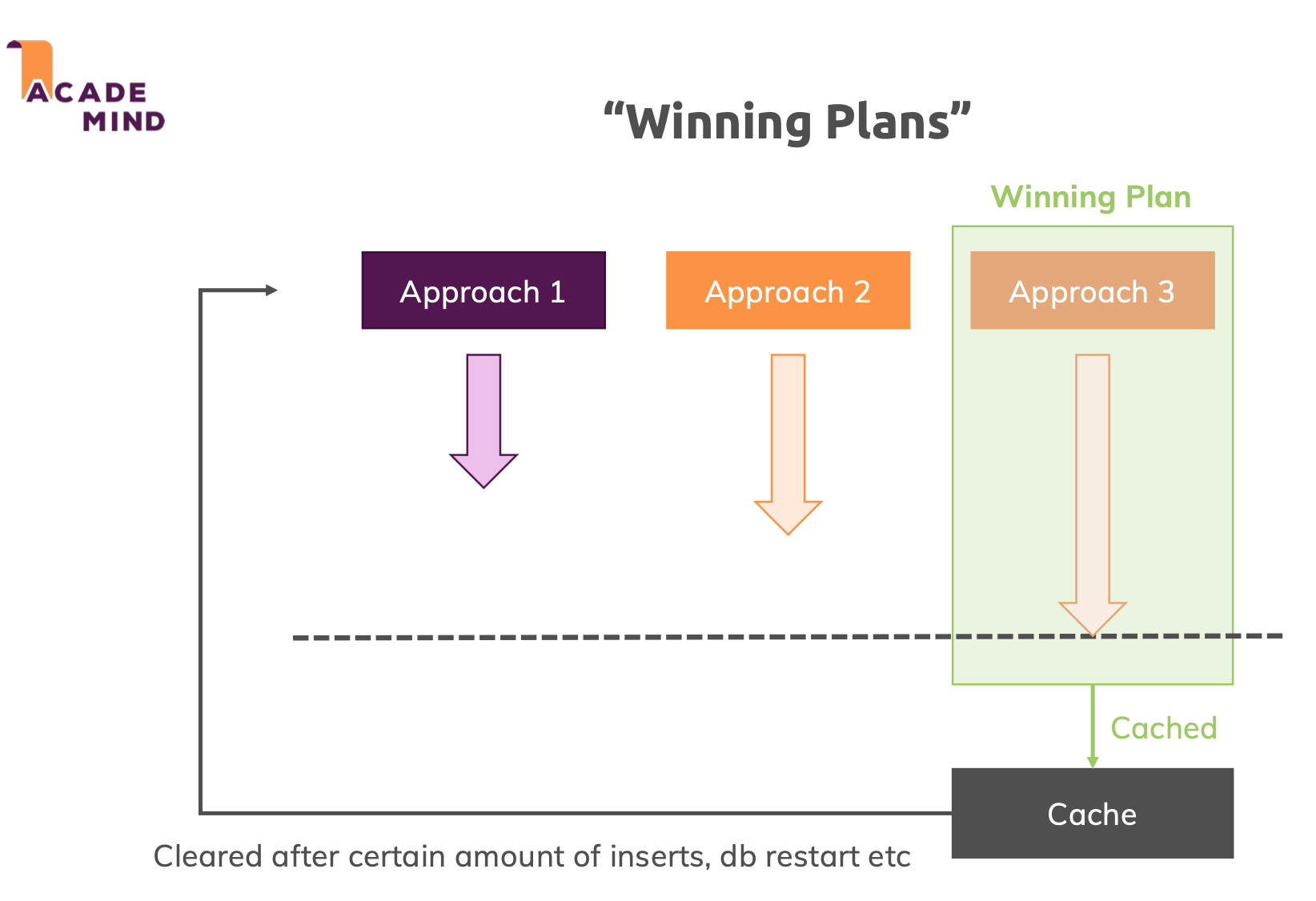
從多種 Plan 當中找出 Winning Plan 也會佔用一些效能,
因此 MongoDB 將 Winning Plan 存入快取,不會每次查詢都找尋 Winning Plan,
而是在某些情況下才重新找尋 Winning Plan。
重新比較 Plan 的時機
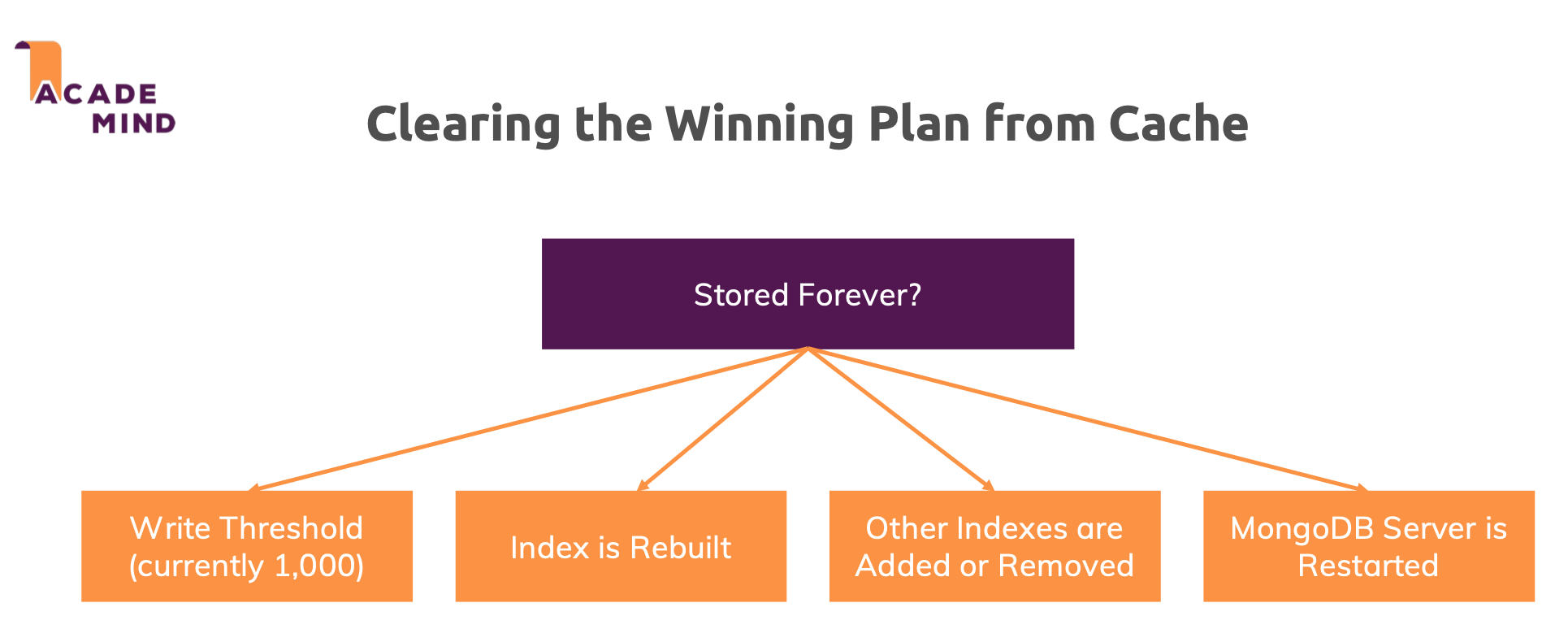
開發者可藉由 explain() 觀察 Plan 之間的差異,例如下列指令可檢視所有 Plan。
db.collection_name.explain("allPlansExecution").find({field1: value1, field2: value2,...})
Text Indexes & Sorting
儲存資料型別為字串時,建立文本索引(Text Index)有利於日後讀取,其效能優於用正規表達式查找。
一個 Collection 只能建立一個文本索引
# 建立文本索引
db.collection_name.createIndex({field: "text"})
# 建立一般索引
db.collection_name.createIndex({field: 1})
# 透過文本索引讀取資料
db.collection_name.find({$text: {$search: "string"}})
Using Text Indexes to Exclude Words
使用文本索引讀取資料時,可將特定字串設為排除條件。
# 讀取含有「read」但不含「not_read」的 Document
db.collection_name.find({$text: {$search: "read -not_read"}})
Setting the Default Language & Using Weights
建立文本索引時,可使用 default_language 設定預設語言,也可使用 weights 設定權重。
使用範例及官方說明文件如下所示。
# 新增文本索引時,設定預設語言及權重。
db.collection_name.createIndex({field1: "text", field2: "text"},
{default_language: "language_name",
weights: {field1: int, field2: int}
})
# 根據文本索引讀取資料,並且顯示其權重分數。
db.collection_name.find({$text: {$search: "value"},
{score: {$meta: "textScore"}}
})
Building Indexes
索引有 Foreground 及 Background 之分。
| Background | Foreground | |
|---|---|---|
| 建立索引時可否操作 Collection | 會阻塞、上鎖 | 可操作、不會阻塞 |
| 存取速度 | 較快 | 較慢 |
db.collection_name.createIndex({field: 1}, {background: true})
Module Summary
What and Why?
- Indexes allow you to retrieve data more efficiently (if used correctly) because your queries only have to look at a subset of all documents
- You can use single-field, compound, multi-key (array) and text indexes
- Indexes don’t come for free, they will slow down your writes
Queries & Sorting
- Indexes can be used for both queries and efficient sorting
- Compound indexes can be used as a whole or in a “left-to-right” (prefix) manner (e.g. only consider the “name” of the “name-age” compound index)
Query Diagnosis & Planning
- Use explain() to understand how MongoDB will execute your queries
- This allows you to optimize both your queries and indexes
Index Options
- You can also create TTL, unique or partial indexes
- For text indexes, weights and a default_language can be assigned